
Oct 13, 2025
Performance Optimization for Reinforcement Learning on AMD GPUs
Featured
AMD GPU
This blog presents our performance optimization and parameter tuning methodology for Reinforcement Learning (RL) workloads using the Verl framework on AMD’s MI300X GPU platform. By capitalizing on the MI300X’s 192GB of unified memory per GPU, we test and optimize the parallelism strategy to minimize the inter-GPU communication on the three phases in GPRO; we also explore the performance with various parallelisms and reveal the nontrivial relationship between the parallelism degree and performance.
Key Takeaways
- Detailed performance breakdown on the three execution phases in RL
- Performance tuning across 3D parallelisms to identify optimal configurations for RL phases
- Scalability study across multiple AMD GPUs
- Identification of performance bottleneck in RL
Background on RL and Verl
Reinforcement Learning (RL) is a critical technique in the training process of reasoning models such as OpenAI O1 [1] and DeepSeek R1 [2]. RL enhances the models' performance by introducing a reward mechanism that usually learns from human preferences, verifiable codes, or problems.
The typical workflow of RL, which is often based on the Proximal Policy Optimization (PPO) algorithm [3], involves three phases (i.e., the rollout phase, inference phase, and training phase) that perform different types of tasks on four distinct Large Language Model (LLM) instances including Actor (training target), Reference, Critic, and Reward [4]. Specifically, during the rollout phase, the Actor model will generate outputs auto-regressively based on the provided prompts. Then, during the inference phase, the full sequences (i.e., prompt+output) are evaluated by the Reward model, which generates a reward (usually a floating point number) per sequence. The full sequences are also evaluated by the Reference model and the Critic model, which both generate log probabilities of each token (a list of floating point numbers). Moreover, the full sequences are processed by the initial checkpoint of the Actor model to get the old log probabilities for the KL divergence calculation later. After that, the generation results as well as the evaluation results are used for calculating the loss and updating the parameters of the Actor and the Critic in the training phase. The rollout phase, inference phase, and training phase together constitute one PPO epoch.
Verl [5] is a RL workflow developed by ByteDance, providing user high-level abstractions to implement different RL algorithms efficiently with different scheduling and co-location strategies.
Evaluation Configuration and Environment
- Task
- GRPO on GSM8K
- Models
- Actor/Reference: Qwen/Qwen2-7B-Instruct
- Reward/Critic: N/A. We use GRPO in our study, hence there is no Critic model. For reward calculation, we use rule-based reward instead of neural network models.
- System Configuration (AMD developer cloud)
- GPU: AMD 8 x MI300X
- VRAM: 1.5 TB in total
- vCPU: 160
- RAM: 1920 GB
- Docker Image
- yushengsuthu/verl:verl-0.4.1_ubuntu-22.04_rocm6.3.4-numa-patch_vllm0.8.5_sglang0.4.6.post4
- Verl Version
- v0.5.0 - e95bd9edf206ee6028b3e0a62221c6fa67931898
Performance Optimization
We run 27 GRPO steps for each configuration shown below.
Rollout Phase
Rollout
- We investigate the impact of tensor parallelism (TP) on rollout performance with Data Parallelism (DP) =1 and Pipeline Parallelism (PP) =1.

Optimization Insight 1: Our results reveal that increasing the TP degree significantly degrades performance due to communication overhead. This reinforces a broader pattern in large-scale AI systems: performance is often determined by orchestration strategy rather than raw hardware.
However, we find that the 192GB memory offered by AMD MI300x is very helpful, allowing us to use just one GPU (using TP=1) to hold the entire model. This improves performance by 2.3x-4.3x, compared with using multiple GPUs based on a larger TP degree.
- With TP=1 and PP=1 fixed, we explore the scaling of DP.


Optimization Insight 2: DP provides substantial performance gain with minimal communication overhead. We achieve a 57% reduction in generation time by scaling from DP=1 to DP=4. While we do not see perfect linear scaling due to variance in response length, DP scaling provides us the most effective optimization for the rollout phase, and the large memory capacity offered by AMD GPUs allows us to easily increase DP (instead of employing TP and DP) for better performance.
Resharding
The rollout phase and training phase can employ different 3D parallelisms (i.e., PP, TP, and DP), which leads to data resharding across the phases. For example, when the rollout phase employs (TP=1, PP=4, and DP=1) and the training phase employs (TP=4, PP=1, and DP=1), the model parameters partitioned at the layer level in PP during the rollout phase have to be re-distributed across GPUs during the training phase such that TP is employed within a layer. Across the phases, data resharding leads to overhead.
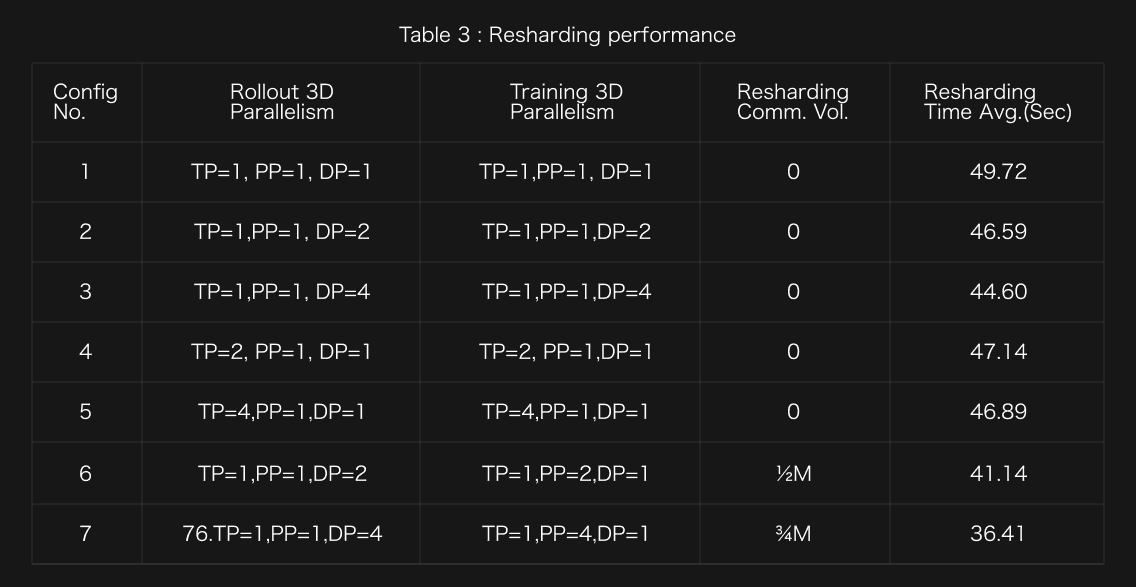
Optimization Insight 3: (1) See the results for the configurations 1, 4, and 5. As we increase the TP degree in the rollout and training phases and the other parallelisms remain the same, the resharding overhead becomes smaller. This is because increasing the TP degree allows such data resharding to happen in parallel, hence decreasing the resharding time.
(2) See the results for the configurations 1, 2, and 3. As we increase the DP degree, the resharding time becomes smaller. We suspect that this decrease in the resharding time comes from the internal optimization in Verl such that GPUs working on different stages of DPs can work in parallel for data format transformation.
Note: The communication volume for resharding is calculated by the following formulation.
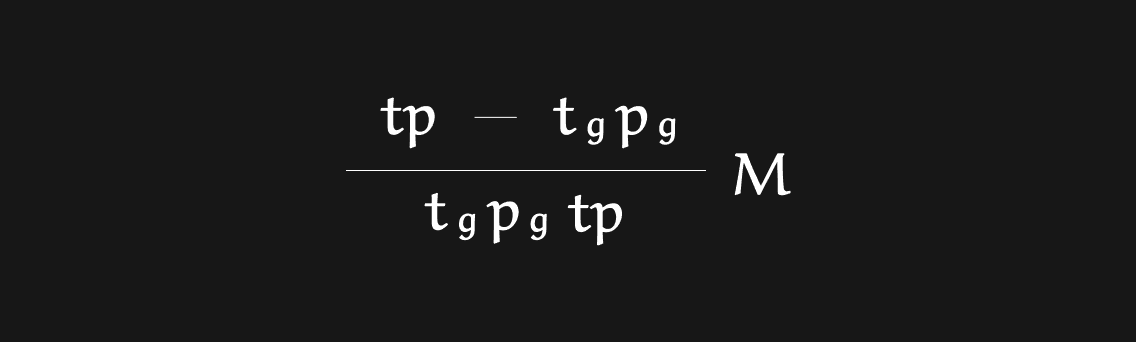
where t, p, tg, and pg represent training TP degree, training PP degree, rollout TP degree, and rollout PP degree, respectively. M stands for the model size of the actor.
Inference/Training Phase
- We evaluate TP scaling with DP=1 and PP=1.
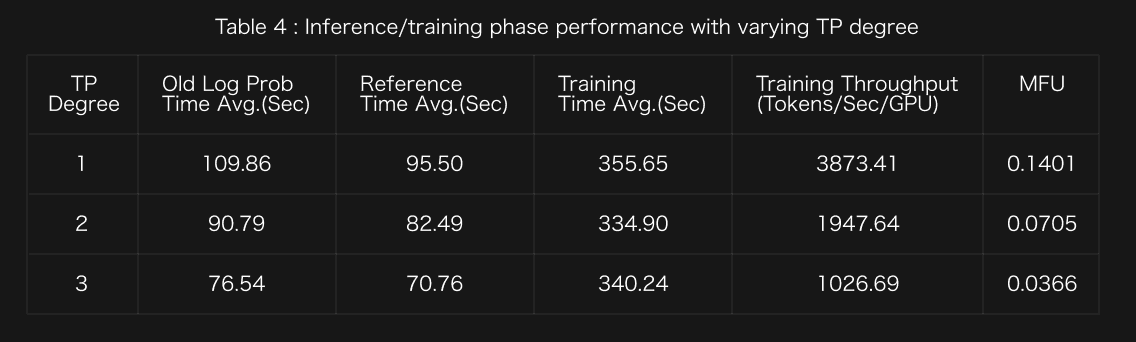
In the above table, MFU or Model FLOPS Utilization is defined as the ratio of the observed throughput (tokens-per-second) relative to the theoretical maximum throughput of a system operating at peak FLOPs.
Optimization Insight 4: In general, MFU is lower when the TP degree is larger than 1. With the sufficient memory offered by AMD GPU, we are able to set the TP degree as 1 to host the whole model in a single GPU, leading to the highest MFU among the three cases shown in the table.
Note: The time difference between the old log prob and reference is due to the model parameter load/offload overhead, since we enable param_offload for the actor model only.
- We evaluate DP scaling with TP=1 and PP=1.
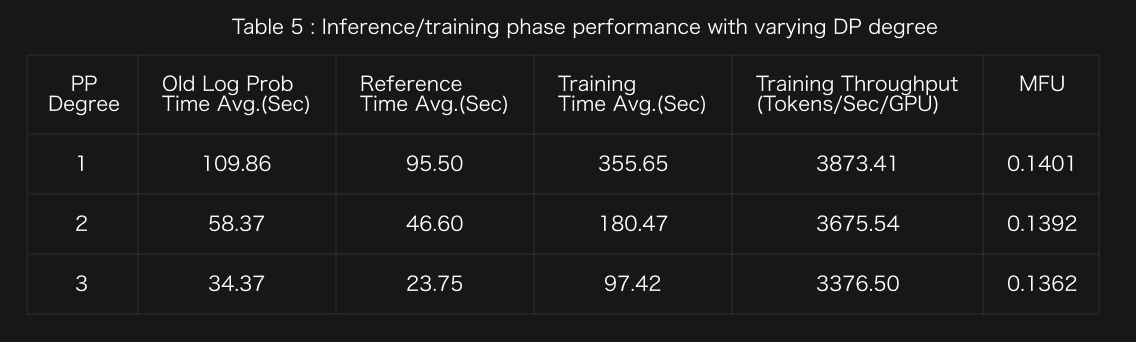
Optimization Insight 5: Increasing the DP degree, we achieve near-linear scaling with minimal MFU degradation. From DP=1 to DP=4, we reduce the training time by 72%.
- We evaluated PP scaling with TP=1 and DP=1.

Optimization Insight 6: Increasing the PP degree, we achieve sub-linear scaling due to pipeline construction overhead and bubble effects. The MFU degradation from 14.01% to 11.28%, indicating that PP=1 was optimal because of the avoidance of unnecessary pipeline complexity.
Conclusions
In this study, we presented our performance optimization methodology for RL workloads using the Verl framework on the AMD MI300X GPU platform. Our investigation focused on tuning 3D parallelism strategies across the rollout, inference, and training phase of the GRPO workflow to minimize inter-GPU communication and identify performance bottlenecks. Our results highlight the strategic advantage of the MI300X’s 192GB HBM3 memory, which enables rollout and training of a 7B parameter model on a single GPU to eliminate communication overhead, thereby improving rollout throughput by 2.3x-4.3x (compared to using a larger TP degree) and maximizing training MFU. Future works will extend the analysis to other RL algorithms and scaling to larger models to analyze TP and PP scalability and enable auto-parallelism.
Appendix
Baseline Script
set -x
export HIP_VISIBLE_DEVICES=3
export RAY_EXPERIMENTAL_NOSET_HIP_VISIBLE_DEVICES=1
export PYTHONUNBUFFERED=1
GPUS_PER_NODE=1
ROLLOUT_TP=1
TRAIN_TP=1
TRAIN_PP=1
ENGINE=vllm
INFERENCE_BATCH_SIZE=40
GPU_MEMORY_UTILIZATION=0.4
YOUR_PROJECT_NAME=amd-megatron-verl-grpo-qwen-gsm8k-report
YOUR_RUN_NAME=ROLLOUTTP$ROLLOUT_TP-TRAINTP$TRAIN_TP-TRAINPP$TRAIN_PP
python3 examples/data_preprocess/gsm8k.py --local_dir $HOME/data/gsm8k-$YOUR_RUN_NAME
gsm8k_train_path=$HOME/data/gsm8k-$YOUR_RUN_NAME/train.parquet
gsm8k_test_path=$HOME/data/gsm8k-$YOUR_RUN_NAME/test.parquet
train_files="['$gsm8k_train_path']"
test_files="['$gsm8k_test_path']"
MODEL_PATH="Qwen/Qwen2-7B-Instruct"
python3 -m verl.trainer.main_ppo --config-path=./config --config-name='ppo_megatron_trainer' \
algorithm.adv_estimator=grpo \
data.train_files=$train_files \
data.val_files=$test_files \
data.train_batch_size=1024 \
data.max_prompt_length=1024 \
data.max_response_length=1024 \
actor_rollout_ref.model.path=$MODEL_PATH \
actor_rollout_ref.actor.optim.lr=1e-6 \
actor_rollout_ref.actor.ppo_mini_batch_size=256 \
actor_rollout_ref.actor.ppo_micro_batch_size_per_gpu=4 \
actor_rollout_ref.actor.use_kl_loss=True \
actor_rollout_ref.actor.kl_loss_coef=0.001 \
actor_rollout_ref.actor.kl_loss_type=low_var_kl \
actor_rollout_ref.actor.megatron.tensor_model_parallel_size=$TRAIN_TP \
actor_rollout_ref.actor.megatron.pipeline_model_parallel_size=$TRAIN_PP \
actor_rollout_ref.actor.megatron.param_offload=True \
actor_rollout_ref.actor.megatron.grad_offload=True \
actor_rollout_ref.actor.megatron.optimizer_offload=True \
actor_rollout_ref.rollout.log_prob_micro_batch_size_per_gpu=$INFERENCE_BATCH_SIZE \
actor_rollout_ref.rollout.tensor_model_parallel_size=$ROLLOUT_TP \
actor_rollout_ref.rollout.name=$ENGINE \
actor_rollout_ref.rollout.gpu_memory_utilization=$GPU_MEMORY_UTILIZATION \
actor_rollout_ref.rollout.n=5 \
actor_rollout_ref.ref.log_prob_micro_batch_size_per_gpu=$INFERENCE_BATCH_SIZE \
actor_rollout_ref.ref.megatron.tensor_model_parallel_size=$TRAIN_TP \
actor_rollout_ref.ref.megatron.pipeline_model_parallel_size=$TRAIN_PP \
algorithm.kl_ctrl.kl_coef=0.001 \
trainer.critic_warmup=0 \
trainer.logger=['console','wandb'] \
trainer.project_name=$YOUR_PROJECT_NAME \
trainer.experiment_name=$YOUR_RUN_NAME \
trainer.n_gpus_per_node=$GPUS_PER_NODE \
trainer.nnodes=1 \Analysis on Data Movement Volume
From the rollout phase to the inference phase
- Prompts: 1 x num_input_tokens, data type: torch.int64
- Responses: 1 x num_response_tokens, data type: torch.int64
- Response mask (for distinguishing LLM generated tokens and tool call results): 1 x num_response_tokens, data type: torch.int64
- Input ids: 1 x (num_input_tokens + num_response_tokens), data type: torch.int64
- Attention masks: 1 x (num_input_tokens + num_response_tokens), data type: torch.int64
- Position ids: 1 x (num_input_tokens + num_response_tokens), data type: torch.int64
From the inference phase to the training phase
- Input ids: 1 x (num_input_tokens + num_response_tokens), data type: torch.int64
- Attention masks: 1 x (num_input_tokens + num_response_tokens), data type: torch.int64
- Position ids: 1 x (num_input_tokens + num_response_tokens), data type: torch.int64
- Responses: 1 x num_response_tokens, data type: torch.int64
- Old log probabilities: 1 x num_response_tokens, data type: torch.float32
- Advantages: 1 x num_response_tokens, data type: torch.float32
References
[1] OpenAI. Learning to reason with LLMs, 2024. URL https://openai.com/index/learning-to-reason-with-llms/.
[2] DeepSeek-AI, Guo, D., Yang, D., Zhang, H., Song, J.,Zhang, R., Xu, R., Zhu, Q., Ma, S., Wang, P., Bi, X.,Zhang, X., Yu, X., Wu, Y., Wu, Z. F., Gou, Z., Shao,Z., Li, Z., Gao, Z., Liu, A., Xue, B., Wang, B., Wu, B.,Feng, B., Lu, C., Zhao, C., Deng, C., Zhang, C., Ruan,C., Dai, D., Chen, D., Ji, D., Li, E., Lin, F., Dai, F., Luo,F., Hao, G., Chen, G., Li, G., Zhang, H., Bao, H., Xu, H., Wang, H., Ding, H., Xin, H., Gao, H., Qu, H., Li,H., Guo, J., Li, J., Wang, J., Chen, J., Yuan, J., Qiu, J.,Li, J., Cai, J. L., Ni, J., Liang, J., Chen, J., Dong, K.,Hu, K., Gao, K., Guan, K., Huang, K., Yu, K., Wang, L.,Zhang, L., Zhao, L., Wang, L., Zhang, L., Xu, L., Xia,L., Zhang, M., Zhang, M., Tang, M., Li, M., Wang, M.,Li, M., Tian, N., Huang, P., Zhang, P., Wang, Q., Chen,Q., Du, Q., Ge, R., Zhang, R., Pan, R., Wang, R., Chen,R. J., Jin, R. L., Chen, R., Lu, S., Zhou, S., Chen, S., Ye,S., Wang, S., Yu, S., Zhou, S., Pan, S., Li, S. S., Zhou,S., Wu, S., Ye, S., Yun, T., Pei, T., Sun, T., Wang, T.,Zeng, W., Zhao, W., Liu, W., Liang, W., Gao, W., Yu, W.,Zhang, W., Xiao, W. L., An, W., Liu, X., Wang, X., Chen,X., Nie, X., Cheng, X., Liu, X., Xie, X., Liu, X., Yang,X., Li, X., Su, X., Lin, X., Li, X. Q., Jin, X., Shen, X.,Chen, X., Sun, X., Wang, X., Song, X., Zhou, X., ang, X., Shan, X., Li, Y. K., Wang, Y. Q., Wei, Y. X., Zhang,Y., Xu, Y., Li, Y., Zhao, Y., Sun, Y., Wang, Y., Yu, Y.,Zhang, Y., Shi, Y., Xiong, Y., He, Y., Piao, Y., Wang, Y.,Tan, Y., Ma, Y., Liu, Y., Guo, Y., Ou, Y., Wang, Y., Gong,Y., Zou, Y., He, Y., Xiong, Y., Luo, Y., You, Y., Liu, Y.,Zhou, Y., Zhu, Y. X., Xu, Y., Huang, Y., Li, Y., Zheng,Y., Zhu, Y., Ma, Y., Tang, Y., Zha, Y., Yan, Y., Ren, Z. Z.,Ren, Z., Sha, Z., Fu, Z., Xu, Z., Xie, Z., Zhang, Z., Hao,Z., Ma, Z., Yan, Z., Wu, Z., Gu, Z., Zhu, Z., Liu, Z., Li,Z., Xie, Z., Song, Z., Pan, Z., Huang, Z., Xu, Z., Zhang,Z., and Zhang, Z. Deepseek-r1: Incentivizing reasoning capability in llms via reinforcement learning, 2025. URL https://arxiv.org/abs/2501.12948.
[3] Schulman, J., Wolski, F., Dhariwal, P., Radford, A., and Klimov, O. Proximal policy optimization algorithms, 2017. URL https://arxiv.org/abs/1707.06347.
[4] Mei, Z., Fu, W., Li, K., Wang, G., Zhang, H., and Wu, Y. Real: Efficient rlhf training of large language models with parameter reallocation, 2025. URL https://arxiv.org/abs/2406.14088.
[5] Guangming Sheng, Chi Zhang, Zilingfeng Ye, Xibin Wu, Wang Zhang, Ru Zhang, Yanghua Peng, Haibin Lin, and Chuan Wu. HybridFlow: A Flexible and Efficient RLHF Framework. In Proceedings of the Twentieth European Conference on Computer Systems (EuroSys), 2025
[6] Agrawal, A., Aga, S., Pati, S., and Islam, M. Optimizing ML Concurrent Computation and Communication with GPU DMA Engines, 2025. URL https://arxiv.org/abs/2412.14335.


