
May 04, 2026
Yotta Labs vs RunPod: Which GPU Platform Is Actually Cheaper for Multi-Provider AI Workloads?
Distributed Inference
Cost Optimization
Yotta Labs is cheaper than RunPod on most key GPUs for multi-provider AI workloads, including RTX 4090, RTX 5090, and H100. RunPod is slightly cheaper on H200, but Yotta Labs offers broader multi-cloud orchestration, lower vendor lock-in, and cross-cloud failover.

Yotta Labs is cheaper than RunPod on most key GPUs for multi-provider AI workloads, including RTX 4090, RTX 5090, and H100 SXM. RunPod is slightly cheaper on H200. The bigger difference is structural: Yotta runs across multiple cloud providers and silicon types (NVIDIA + AMD + Trainium + TPU), with cross-cloud failover and portable deployment configs. RunPod runs on its own infrastructure with NVIDIA-only GPUs.
| Yotta Labs | RunPod | |
| Platform Type | Multi-cloud GPU platform | Single-provider GPU cloud |
| RTX 4090 Rate | $0.38/hr | $0.59/hr |
| RTX 5090 Rate | $0.65/hr | $0.89/hr |
| H100 SXM Rate | $2.56/hr | $2.69/hr |
| H200 SXM Rate | $3.75/hr | $3.59/hr (RunPod lower) |
| Multi-Cloud Support | Yes, NVIDIA, AMD, AWS Trainium, Google TPU | No, RunPod infrastructure only |
| Vendor Lock-in Risk | Low (Launch Templates are portable) | Medium (workloads tied to RunPod) |
| Failover Scope | Cross-cloud | Within-platform |
| AI Gateway (multi-LLM routing) | Yes | Not in product catalog |
| SOC 2 | Type I | Type II |
| Best For | Production multi-GPU, growth-stage AI teams | Developers, researchers, single-cloud inference |
Pricing aside, the two platforms solve meaningfully different problems. Below is the full breakdown.
What Are These Platforms, Really?
RunPod is a GPU cloud that gives developers on-demand access to NVIDIA GPU instances on its own infrastructure. It spans 30+ regions and supports 30+ NVIDIA SKUs, from RTX 4090s to H200s. Its serverless product lets teams scale inference endpoints without managing pods manually. RunPod is fast, developer-friendly, and competitively priced for individual or small-team workloads.
Yotta Labs is a multi-cloud GPU platform, a managed layer that sits above GPU compute from multiple providers simultaneously. Rather than operating as a single cloud, Yotta unifies fragmented GPU capacity across emerging clouds, micro data centers, and hyperscalers into a single API. Teams deploy workloads once; Yotta handles routing, scheduling, and failover across NVIDIA, AMD, AWS Trainium, and Google TPU infrastructure.
The clearest framing: RunPod gives you GPU instances. Yotta Labs gives you a managed compute layer that runs across multiple GPU providers on your behalf.
This distinction matters most when evaluating total cost of ownership for multi-provider AI workloads.
Pricing and Cost Comparison
Yotta Labs Pod Pricing
Rates from Yotta Labs’ GPU pod catalog as of April 30, 2026:
| GPU | VRAM | RAM | vCPU | Price/hr |
| RTX 5090 | 32 GB | 115 GB | 14 | $0.65 |
| RTX 4090 | 24 GB | 115 GB | 30 | $0.38 |
| RTX PRO 6000 | 96 GB | 119 GB | 14 | $1.35 |
| RTX A6000 | 48 GB | 24 GB | 6 | $0.45 |
| RTX 6000 Ada | 48 GB | 60 GB | 10 | $0.97 |
| A100 PCIe 80G | 80 GB | 75 GB | 15 | $0.92 |
| A100 SXM 80G | 80 GB | 120 GB | 22 | $1.48 |
| H100 | 80 GB | 185 GB | 22 | $2.56 |
| H200 | 141 GB | 181 GB | 22 | $3.75 |
| B200 | 180 GB | 184 GB | 30 | $5.37 |
| B300 | 262 GB | 275 GB | 30 | $7.64 |
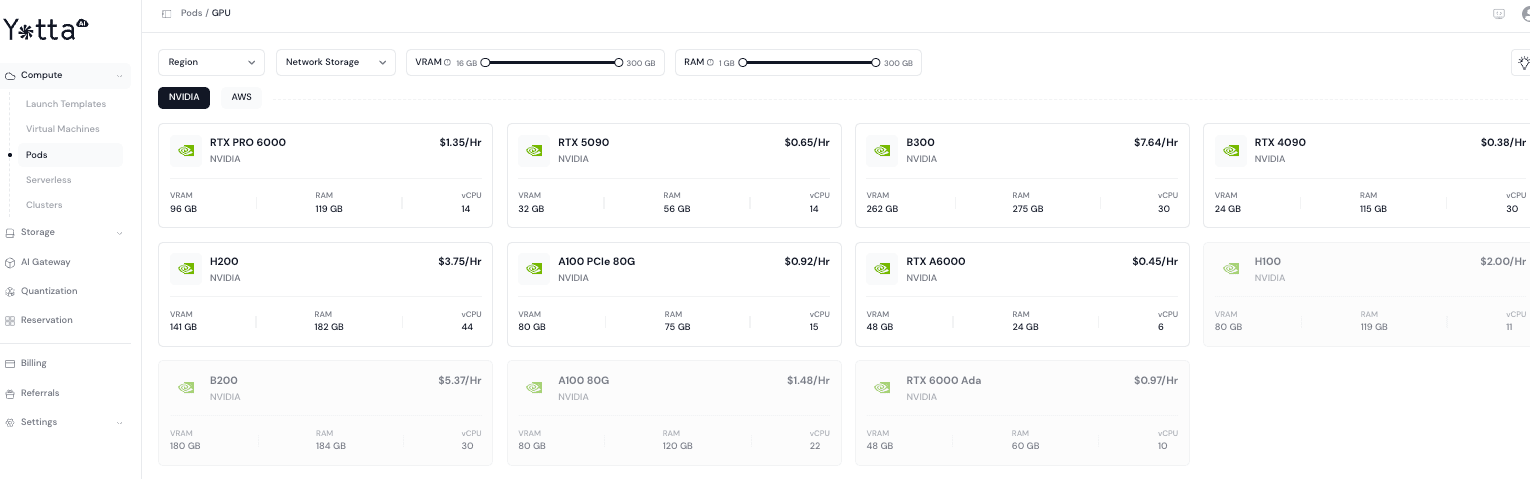
Yotta Labs deploys GPU pods in under 3 seconds, with no egress fees and pay-as-you-go billing.
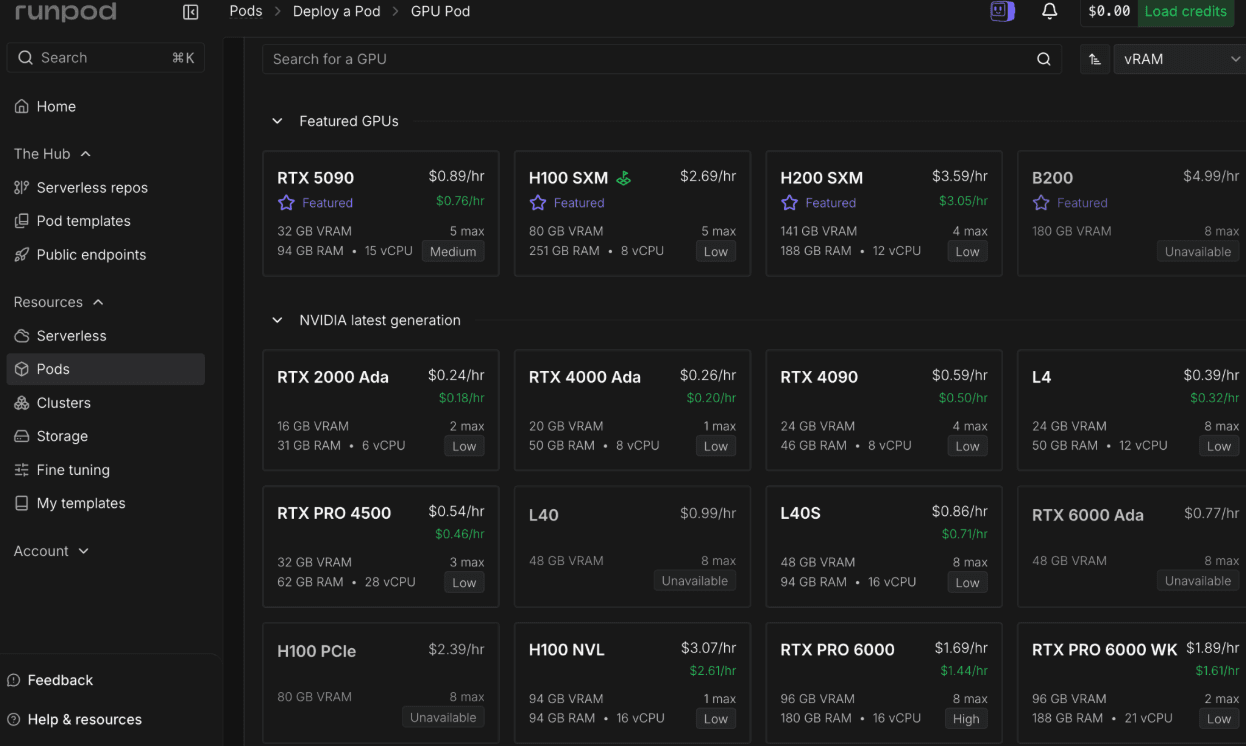
RunPod Pricing Structure
RunPod operates across three access tiers (rates from runpod.io/pricing as of April 30, 2026):
- Community Cloud connects users to peer-sourced GPUs at the lowest per-hour rates, billed per second. Suitable for experimentation; reliability varies across hosts.
- Secure Cloud adds $0.10–$0.40/hr for dedicated, SOC 2-compliant infrastructure. The appropriate tier for production workloads.
- Serverless provides automatic scaling across two worker modes. Flex Workers scale up on demand and return to idle after jobs complete. Active Workers stay always-on with up to a 30% discount and eliminate cold starts. Serverless pricing typically runs 2–3× higher than pod pricing for the same GPU.
Secure Cloud rates for comparable SKUs:
| GPU | RunPod Secure Cloud Rate |
| RTX 4090 | $0.59/hr |
| RTX 5090 | $0.89/hr |
| A100 SXM 80GB | $1.49/hr |
| H100 SXM 80GB | $2.69/hr |
| H200 SXM 141GB | $3.59/hr |
Direct Rate Comparison
| GPU | Yotta Labs | RunPod Secure Cloud | Difference |
| RTX 4090 | $0.38/hr | $0.59/hr | Yotta ~36% lower |
| RTX 5090 | $0.65/hr | $0.89/hr | Yotta ~27% lower |
| A100 SXM 80G | $1.48/hr | $1.49/hr | Comparable |
| H100 SXM | $2.56/hr | $2.69/hr | Yotta ~5% lower |
| H200 SXM | $3.75/hr | $3.59/hr | RunPod ~4% lower |
On mid-range and consumer GPU SKUs — where fine-tuning and development spend accumulates fastest — Yotta Labs prices noticeably lower. The H200 SXM is the one exception at the high end. As of April 2026, RunPod also showed H200 availability as Low; this is volatile and worth checking against current capacity.
What This Looks Like in Real Spend
For a team running 8 GPUs 24/7 for a month (730 hours), the per-hour gap compounds:
| Configuration | Yotta Labs (monthly) | RunPod Secure Cloud (monthly) | Monthly difference |
| 8× RTX 4090 | $2,219 | $3,446 | $1,226 lower on Yotta |
| 8× RTX 5090 | $3,796 | $5,198 | $1,402 lower on Yotta |
| 8× H100 SXM | $14,950 | $15,710 | $759 lower on Yotta |
| 8× H200 SXM | $21,900 | $20,964 | $936 lower on RunPod |
Annualized, that’s roughly $9,000–$17,000 in savings per 8-GPU cluster on Yotta for the consumer and H100 SKUs. For H200-heavy fleets, RunPod is currently the cheaper option per hour.
Yotta also reports up to 50% fewer GPUs required on reinforcement learning workloads vs a standard 128× H100 baseline, attributed to software-level optimizations. This is a vendor-published benchmark; teams should validate on their own workload before factoring it into procurement.
Hidden Cost Factors
Neither platform charges for data ingress or egress — an important advantage over hyperscalers like AWS. Storage on RunPod starts at $0.05/GB/month and Yotta Labs charges for 0.036/GB/month. Both offer pay-as-you-go billing with no long-term commitments, and discounts for reserved capacity.
Where total cost of ownership diverges is at the infrastructure management layer. RunPod focuses on GPU compute; databases, CI/CD pipelines, monitoring, and cross-region routing logic require additional tooling. Yotta Labs builds scheduling, failure recovery, and multi-provider routing into the platform itself, reducing the engineering overhead of managing heterogeneous infrastructure.
Multi-Cloud Flexibility and Vendor Lock-in
This is where the two platforms diverge most sharply, and where the case for Yotta Labs becomes strongest for production AI teams.
RunPod is a single-provider platform. It operates across 30+ regions for geographic diversity, but all compute runs on RunPod’s own infrastructure. If a specific GPU SKU becomes unavailable due to demand spikes (as has happened with H200s and RTX 5090s), there’s no automatic path to source equivalent capacity from another provider. Teams either wait or manually migrate workloads.
Yotta Labs is built around the assumption that GPU supply is fragmented and heterogeneous by default. Launch Templates let engineering teams define workload configurations once and deploy them across different GPU providers without re-architecting. When capacity is unavailable from one source, the platform routes to the next available option automatically. This means teams can access RTX 5090s, H200s, and B300s without depending on any single cloud’s availability window.
For teams building production systems that can’t tolerate unexpected capacity gaps, this is a different failure model — not a minor feature distinction.
Yotta Labs also supports multi-silicon orchestration across NVIDIA, AMD, AWS Trainium, and Google TPUs. RunPod’s catalog is NVIDIA-only. As AI infrastructure continues to diversify across silicon vendors, single-silicon lock-in carries the same category of risk as single-cloud lock-in.
Serverless Elasticity and Cold Start Performance
Both platforms offer serverless GPU deployment. The scope of that elasticity differs.
RunPod’s serverless product is mature and well-optimized. Its FlashBoot technology achieves sub-200ms cold starts on roughly 48% of serverless jobs, with larger containers initializing in 6–12 seconds. Flex Workers scale to zero when idle and scale up on traffic spikes. For bursty inference workloads on a single provider, RunPod serverless is one of the fastest options on the market.
Yotta Labs deploys GPU pods in under 3 seconds and scales AI applications automatically across regions. The serverless architecture extends beyond a single provider’s capacity, so scale-out during traffic spikes can draw from multiple clouds rather than being constrained by one platform’s worker pool. For workloads with unpredictable or globally distributed traffic, this cross-provider elasticity provides additional headroom.
Practical takeaway: RunPod serverless is excellent if your traffic pattern fits inside a single platform’s capacity. Yotta Labs serverless is the stronger choice when workloads need to scale across GPU types, regions, or cloud providers simultaneously.
Production-Readiness and Enterprise Features
| Feature | Yotta Labs | RunPod |
| SOC 2 Compliance | Type I | Type II |
| Cross-Cloud Failover | Yes | No |
| Multi-Silicon Support | NVIDIA, AMD, Trainium | NVIDIA only |
| AI Gateway (multi-LLM routing) | Yes | Not in product catalog |
| Built-in Quantization Tools | Yes | Bring-your-own (vLLM, AWQ, etc.) |
| Launch Templates (portable across providers) | Yes | Quick Deploy (within RunPod only) |
Yotta Labs is SOC 2 certified and built for distributed multi-cloud environments. Its AI Gateway provides a unified API that routes requests across multiple LLM providers for cost, performance, and availability — a capability with no equivalent in RunPod’s product catalog as of this writing.
RunPod is independently audited for SOC 2 Type II compliance and runs production workloads for a wide range of AI teams. For teams that only need single-provider GPU compute, RunPod’s enterprise offering is solid.
For teams with more complex requirements — cross-region failover, multi-LLM routing, or hardware-level optimizations across AMD and NVIDIA kernels — Yotta Labs provides infrastructure RunPod doesn’t.
When to Choose RunPod vs Yotta Labs
Choose RunPod if:
- You’re an individual developer or researcher running experiments
- Your workloads are predictable and single-cloud GPU access is sufficient
- You’re prototyping or fine-tuning models at small to medium scale
- You want the fastest path from zero to a running GPU pod, with extensive documentation and community examples
- You need sub-200ms serverless cold starts within a single platform
Choose Yotta Labs if:
- You’re building production AI infrastructure at a growth-stage or enterprise company
- You need GPU compute across multiple providers to avoid availability bottlenecks
- Your engineering team is scaling distributed training or inference across heterogeneous hardware
- You want Launch Templates to standardize deployments and prevent vendor lock-in
- You need a unified AI Gateway to route across multiple LLM providers alongside compute
- You’re running consumer-class GPU fleets (RTX 4090/5090) at scale, where the per-hour gap compounds quickly
The two platforms can coexist in a stack. Some teams use RunPod for development pods and Yotta Labs for production multi-cloud deployments.
Frequently Asked Questions
Is Yotta Labs cheaper than RunPod for multi-GPU AI workloads?
On most mid-range and consumer GPU SKUs, yes. RTX 4090 runs at $0.38/hr on Yotta vs $0.59/hr on RunPod Secure Cloud — a 36% gap. RTX 5090 is 27% lower on Yotta ($0.65 vs $0.89/hr). H100 SXM is slightly lower on Yotta ($2.56 vs $2.69/hr); A100 SXM is essentially the same. The exception is the H200 SXM, where RunPod is currently slightly cheaper ($3.59 vs $3.75/hr). On RL workloads, Yotta also reports up to 50% fewer GPUs required vs a 16× H100 baseline — a vendor benchmark worth validating on your own workload.
Does RunPod support multi-cloud GPU orchestration?
No. RunPod operates its own infrastructure across 30+ regions but doesn’t orchestrate workloads across external cloud providers like AWS, GCP, Azure, or other GPU clouds. All compute runs within RunPod’s own platform. Yotta Labs is purpose-built for multi-cloud orchestration, routing workloads across multiple providers through a unified control plane.
What are Launch Templates in Yotta Labs and how do they compare to RunPod’s deployment process?
Launch Templates are portable deployment configurations that define how AI workloads should be deployed, scaled, and migrated across different GPU providers. Teams configure a workload once, and the template handles provider-agnostic deployment. RunPod offers Quick Deploy templates and endpoint configurations within its own platform, but these aren’t portable across external providers. For teams concerned about vendor lock-in, Launch Templates provide a migration path RunPod’s templates don’t.
Which platform handles automatic failure handover better?
Both handle within-platform failover. Yotta Labs extends this to cross-cloud automatic failure handover — if compute on one provider fails or becomes unavailable, jobs are rerouted to another provider automatically. RunPod’s failover is limited to its own infrastructure. For production systems where availability matters across providers, Yotta Labs has a stronger failover posture.
Can I access RTX 5090 and H200 GPUs on both platforms?
Yes. Yotta Labs lists RTX 5090 pods at $0.65/hr and H200 pods at $3.75/hr. RunPod lists RTX 5090 Secure Cloud at $0.89/hr and H200 SXM at $3.59/hr — RunPod is slightly cheaper on H200. As of April 2026, RunPod showed H200 availability as Low, while Yotta Labs’ multi-provider sourcing reduces capacity-gap risk on high-demand SKUs. For teams targeting B300 ($7.64/hr on Yotta Labs), RunPod currently shows it as unavailable.
How does Yotta Labs compare to Vast.ai or Together AI?
Vast.ai is a peer-to-peer GPU marketplace — cheap per-hour rates, but no centralized failover, no multi-cloud routing, and host reliability varies. It fits short experiments, not production. Together AI is a managed inference API — clean to integrate with, but you don’t choose the underlying hardware, see GPU-level cost, or control deployment. Yotta Labs sits in a different category: hardware control of a marketplace, the reliability of a managed platform, and multi-cloud routing neither provides. For a deeper breakdown, see our GPU cloud guide for AI researchers.
Is Yotta Labs production-ready compared to RunPod for enterprise AI workloads?
Yes. Yotta Labs is SOC 2 certified, built for long-running training and inference workloads, and designed with enterprise security controls for multi-cloud environments. RunPod is also SOC 2 Type II certified and used in production by a wide range of AI teams. The distinction for enterprise teams: Yotta Labs includes cross-cloud failover, multi-silicon support, and an AI Gateway as part of the platform — capabilities that typically require separate tooling when using RunPod for complex production deployments.
What is the main difference between Yotta Labs and RunPod for avoiding vendor lock-in?
RunPod is a single-provider platform. Deploying deeply means workload configurations, storage, and endpoint routing are built around RunPod’s ecosystem; migrating to another provider requires re-architecture. Yotta Labs is designed to prevent this. Launch Templates, multi-cloud routing, and multi-silicon support mean teams can move workloads across providers without rebuilding deployment configurations. For growth-stage AI companies that anticipate changing infrastructure as hardware and pricing evolve, Yotta Labs has meaningfully lower architectural lock-in.
Try Yotta Labs
If your workloads run mostly on consumer GPUs (RTX 4090/5090) or H100 SXM, the per-hour savings on Yotta Labs compound quickly — roughly $9,000–$17,000 per year per 8-GPU cluster. If you’re already managing GPU compute across multiple providers, Launch Templates and cross-cloud failover replace a meaningful chunk of in-house ops work.
→ Compare prices on yottalabs.ai/pricing
→ Apply for $1,000 in academic GPU credits if you’re an independent researcher or academic team


