Mar 17, 2026
Mini-SGLang-Neuron: Bringing Lightweight LLM Inference to AWS Trainium and Inferentia
Featured
SGLang
RadixArk
A lightweight inference framework integrating SGLang with AWS Neuron to enable efficient LLM serving on Trainium and Inferentia across multi-hardware environments.
Yotta Labs, RadixArk, SGLang

AI applications are scaling at an unprecedented pace. From chat assistants and coding copilots to search, recommendation, and increasingly complex agentic workflows, modern products are becoming deeply dependent on large language model (LLM) inference in production. At the same time, generative workloads are expanding beyond text —— diffusion models are powering a new wave of image, video, and multimodal applications. As adoption accelerates across both LLMs and diffusion models, the demands on inference infrastructure grow accordingly. Delivering a strong model is no longer sufficient—systems must also meet strict requirements for latency, throughput, and cost efficiency at scale.
This shift has elevated AI hardware to a first-class concern in the stack. While NVIDIA GPUs remain the most widely adopted platform, they are no longer the only viable option. Emerging accelerators such as AWS Trainium and Inferentia, powered by the AWS Neuron software stack, offer compelling alternatives with differentiated performance and cost profiles. In practice, no single hardware platform is optimal for all workloads —— efficiency increasingly depends on aligning model serving strategies with specific workload characteristics, whether for token-heavy LLM inference or compute-intensive diffusion pipelines.
As a result, inference frameworks must evolve to support a broader range of hardware backends. In a world of rapidly diversifying AI infrastructures, flexibility is no longer optional. To achieve optimal performance and cost efficiency, serving systems need to move beyond single-platform assumptions and embrace a truly multi-cloud, multi-silicon paradigm.
Introducing Mini-SGLang-Neuron
To explore this direction, we introduce Mini-SGLang-Neuron —— a lightweight inference framework that integrates Mini-SGLang with the AWS Neuron stack to enable high-performance LLM serving on Trainium and Inferentia.
Mini-SGLang-Neuron is designed as an early but meaningful step toward a broader goal: bringing the open-source SGLang inference engine to AWS Neuron-based hardware. Rather than attempting a full port upfront, we focus on building a minimal, transparent system that captures the core serving abstractions while adapting them to a new hardware backend.
The project deliberately balances two priorities. First, it keeps the runtime compact and readable, making it easier to understand, extend, and debug. Second, it implements a set of practical optimizations that directly impact real-world serving performance.
Concretely, Mini-SGLang-Neuron includes features such as radix attention caching for KV cache reuse across shared prefixes, chunked prefill to reduce memory pressure for long-context inputs, tensor parallelism across multiple Neuron cores, and kernel-level optimizations for critical execution paths. Together, these capabilities make the framework both approachable for developers and effective for production-oriented workloads.
Quick Start
One of the fastest ways to get started with Mini-SGLang-Neuron is to launch a Trainium1 (Trn1) instance on Yotta Labs and run the runtime in shell mode for interactive testing.
Yotta Labs recently introduced AWS Trainium1 support in its console, making it straightforward to experiment with Neuron-based workloads alongside other accelerators. To begin, log in to console.yottalabs.ai, navigate to Virtual Machines, and launch a Trainium1-backed instance. This provides a unified control plane for benchmarking and development across multi-cloud, multi-silicon environments.
Once your instance is ready, clone the repository and install dependencies:
git clone https://github.com/yottalabsai/mini-sglang-neuron.git
cd mini-sglang-neuron && bash init_setup.shThen launch the runtime in shell mode:
export TP_SIZE=2
export NEURON_RT_NUM_CORES="${TP_SIZE}"python -m minisgl \
--model-path "Qwen/Qwen3-0.6B" \
--dtype bfloat16 \
--tp-size "$TP_SIZE" \
--max-running-requests 6 \
--max-seq-len-override 4096 \
--num-pages 10192 \
--port 1919 \
--shell-modeThis starts an interactive session directly in the terminal, allowing you to quickly validate model behaviors, test prompts, and iterate on configurations with minimal setup overhead. It’s a simple but effective way to explore LLM inference on Trainium before moving to more advanced serving scenarios.
Benchmarking
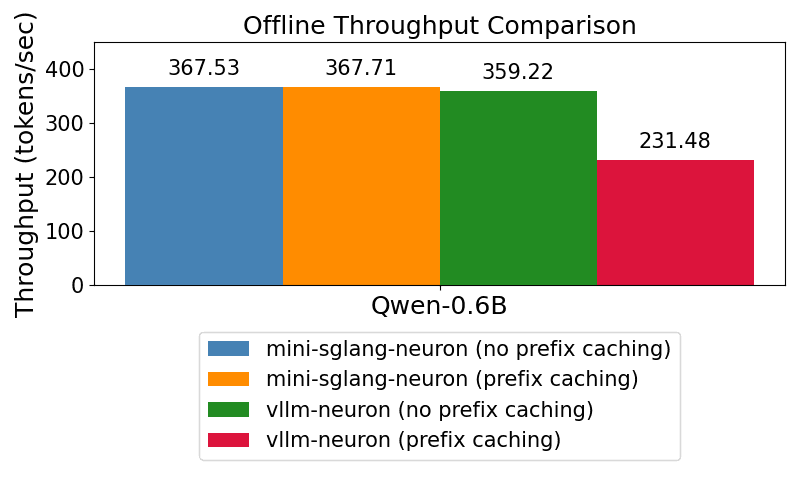
To evaluate serving performance, we benchmark Mini-SGLang-Neuron against vLLM-Neuron (0.4.1) across both offline and online settings, using the Qwen3-0.6B model on a Trainium instance with two Neuron cores.
The two benchmark modes target different aspects of system performance.
In offline benchmarking, the primary metric is throughput. The goal is to measure how efficiently the system processes and generates tokens under batch-style workloads. This setting highlights overall hardware utilization and raw serving efficiency under sustained load.
In online benchmarking, the evaluation becomes more nuanced. In addition to throughput, we focus on user-facing latency metrics such as TTFT (time to first token) and TPOT (time per output token). These metrics better capture real-world interactive scenarios, where systems must balance responsiveness with concurrent request handling.
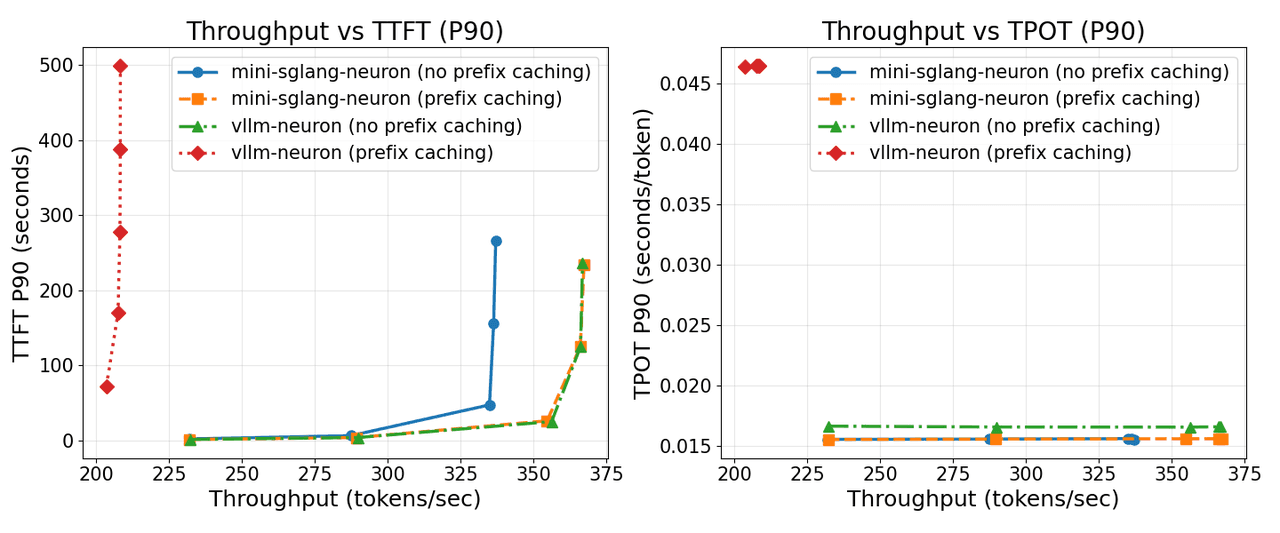
These comparisons are important because they demonstrate where a lightweight runtime can still compete effectively. Mini-SGLang-Neuron is not just a minimal implementation for learning and experimentation—it is a deliberate attempt to build a performant, Neuron-native serving framework and validate its design against a strong baseline.
Looking Ahead
Mini-SGLang-Neuron is just a starting point. Our next step is to deepen the integration between SGLang and the AWS Neuron stack, with the goal of unlocking a richer open-source inference ecosystem on AWS custom AI hardware.
As the hardware landscape continues to diversify, software portability and backend flexibility will become increasingly critical. The future of inference will not be tied to a single accelerator or cloud—it will be defined by the ability to seamlessly adapt across them.
Projects like Mini-SGLang-Neuron are early steps in that direction. By lowering the barrier to running efficient inference on non-GPU platforms, we aim to make it easier for developers and researchers to explore, benchmark, and build on emerging hardware—and ultimately move toward a truly multi-cloud, multi-silicon serving paradigm.
Get Involved
Mini-SGLang-Neuron is open source and available on GitHub:
Repository: https://github.com/yottalabsai/mini-sglang-neuron
We welcome contributions from the community. Areas such as performance optimization, model support, documentation, benchmarking, and Neuron-specific enhancements are all valuable directions for collaboration.
For partnership opportunities or deeper collaboration, feel free to reach out through Yotta Labs’ official channels: https://www.yottalabs.ai/support