One API.
Every AI Models.
No Vendor Lock-in.
Yotta AI Gateway gives you a single OpenAI-compatible endpoint to access 50+ LLM, image,
and video generation models — with intelligent routing, automatic fallback, and real-time usage insights.
15+
Providers
50+
AI Models
< 50ms
Avg Latency
99.9%
Uptime SLA
Supported Providers
How It Works
One line of code change.
Infinite model access.
Step 1: Point to Yotta Gateway
Replace your base_url with https://gateway.yottalabs.ai/v1. Your existing OpenAI SDK code runs as-is — no refactoring needed.
Step 2: Select Any Model
Use provider/model notation to switch between 50+ models instantly — openai/gpt-4o, anthropic/claude-3-7-sonnet, meta/llama-3.3-70b, and more.
Step 3: Yotta Handles the Rest
We route each request to the best endpoint by cost, latency, or quality — and automatically failover if a provider goes down. You focus on building.
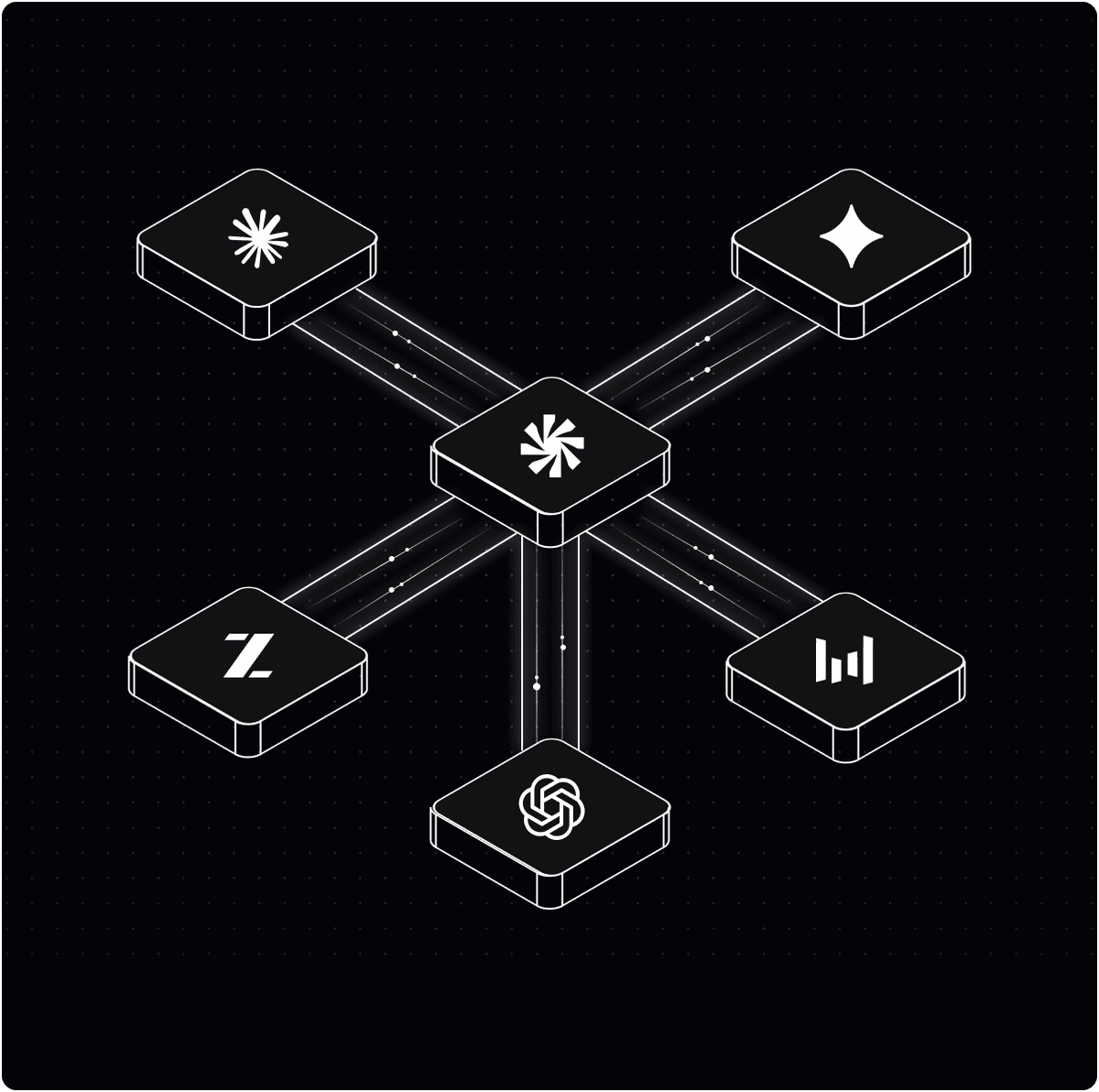
Intelligent Routing
Route to the right model,
at the right cost.
Unlike pure API proxies, Yotta Gateway has a unique advantage: it owns the compute layer. Route not just between API providers, but directly to Yotta's optimized inference endpoints on NVIDIA, AMD, and AWS Trainium hardware.
Cost-Optimized Routing
Always routes to the lowest-cost provider per request, without sacrificing quality
Latency-First Routing
Dynamically selects the fastest available endpoint for time-sensitive workloads
Automatic Fallback
Silently fails over to backup providers on errors or rate limits. Zero downtime for your users
Quality-Based Routing
Matches each request to the best-performing model for its task — balancing output quality, speed, and cost
Model Catalog
Every major model,
One unified endpoint.
LLMs, image generators, video models, and embedding models — all accessible
via the same OpenAI-compatible API. Switch models without touching your integration code.

Nano Banana Pro
Text-to-Image
Nano Banana Pro is a Text-to-Image model developed by Google DeepMind, designed to generate high-quality images from natural language prompts with strong structural consistency and fine visual details. The model performs well in handling complex prompts and diverse styles, making it suitable for creative design, marketing visuals, and other professional image generation use cases.

Seedance 1.5 Pro
Text-to-Video
Seedance 1.5 Pro is a text-to-video model developed by ByteDance. It generates high-quality, realistic videos with fluent motion, consistent visuals, and strong prompt adherence. The model supports adjustable video duration, multiple aspect ratios, reproducible generation via random seeds, and synchronized audio output, making it suitable for advertising, creative content production, short dramas, and professional video creation workflows.

Kling v3 Pro
Image-to-Video
Kling v3 Pro is an advanced image-to-video generation model developed by Kling AI. It transforms static images into high-fidelity, cinematic videos with highly realistic motion, strong temporal consistency, and improved prompt adherence. The model supports complex scene dynamics, stable character identity across frames, and longer video generation, making it suitable for storytelling, advertising, and high-end creative production workflows.

Hailuo 2.3 Fast
Image-to-Video
Hailuo 2.3 Fast is a lightweight and high-efficiency image-to-video model developed by MiniMax. It focuses on fast generation speed while maintaining strong visual quality and motion stability. The model is optimized for low-latency workflows, enabling rapid iteration of creative ideas, and is suitable for social media content, short-form videos, and real-time creative exploration.

Veo 3.1
Image-to-Video
Veo 3.1 is a state-of-the-art video generation model developed by Google. It produces highly realistic and cinematic videos with advanced understanding of physics, lighting, and scene composition. The model supports image-to-video generation with strong temporal coherence, natural motion transitions, and high-fidelity detail, making it suitable for professional filmmaking, advertising, and high-end visual production.

Grok Imagine
Text-to-Image
Grok Imagine is an image-to-video generation capability developed by xAI. It transforms static images into dynamic short videos with strong prompt responsiveness and flexible style control. The model supports expressive motion generation and fast creative iteration, making it suitable for experimental content, stylized visuals, and rapid concept prototyping.
Developer Experience
Drop-in replacement
for OpenAI SDK.
Change one line of code. Access everything. Yotta Gateway is 100% OpenAI-compatible — no new SDK, no refactoring, no migration headaches. Just point your existing code at our endpoint and you're done.
Plug-and-play with LangChain, LlamaIndex, and Vercel AI SDK
Full streaming response support
Function calling, tool use & structured outputs
Vision, multimodal & audio models
Batch API ready for high-volume, cost-efficient workloads
Python
curl https://gateway.yottalabs.ai/api/maas/chat/completions \
-H "Content-Type: application/json" \
-H "Authorization: Bearer $YOUR_API_KEY" \
-d '{
"model": "claude-sonnet-4-6",
"messages": [{"role": "user", "content": "Who are you"}],
"stream": true
}'Your AI Stack, Simplified.
Start Building Today.
No credit card required. Get your API key in under 5 minutes and access 50+ models instantly
or talk to our team about enterprise-grade routing, SLAs, and dedicated support.